HashMaps are one of the most useful data structures. Find the number of employees under every employee is a problem that reminds me of the famous movie’s inception. Akin to dream in a dream. Here, we have an employee working under an employee and so on.
Table of Contents
Problem Statement
So, what are we to make out of this issue?
Well. Someone has assigned US this tedious task of counting the number of employees one has working under them.
Firstly, let us cover with a test case the way the problem has been presented to us:
We are given pairs of characters with the first one being the employee and the second being the manager. We are to find the number of employees assigned to others.
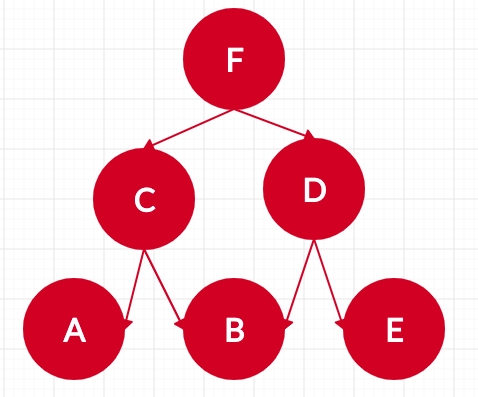
Approach and Ideology
There are a host of ways in which the problem can be approached. However, most of the ways are either heavy on time or on space. The one I have mentioned here seemed the best way to go about it.
- Firstly, while finalizing data structures I realized that Hashmaps was the best way to go about the problem
- Secondly, I realized if used efficiently. Just one loop was enough.
- We are maintaining a hashmap.
- The keys of the hashmap are the employees
- The value of the hashmap is the count of employees under them
- We are running a loop.
- We look each time if we already have a key for the manager
- If we do, we add 1 to the previous value
- We look each time if we already have a key for the employee
- If we do, we the people working under him to our network
Java Code for Find Number of Employees Under every Employee
void group(lisa[][],int x,int y)
{
unordered_map<char,int>store;
for(int i=0;i<x;i++)
{
if(store.find(lisa[i][1])!=lisa.end())
{
if(store.find(lisa[i][0])!=lisa.end())
store[lisa[i][1]]=lisa[[i][0]]+store[lisa[i][1]]+1;
else
store[lisa[i][1]]=store[lisa[i][1]]+1;
else
store.put[lisa[i][1]]=1;
}
for (int data : store)
{
cout<<"Key = " + datagetKey() + ", Value = "+entry.getValue());
}
}
int main()
{
Character[6][2]lisa;
lisa[0][0]='A';
lisa[0][1]='C';
lisa[1][0]='B';
lisa[1][1]='C';
lisa[2][0]='C';
lisa[2][1]='F';
lisa[3][0]='D';
lisa[3][1]='E';
lisa[4][0]='E';
lisa[4][1]='F';
lisa[5][0]='F';
lisa[5][1]='F';
group(lisa,6,2);
}It can be seen how we transition from HashMap to unordered_map as we go from Java to C++.
C++ Code for Find Number of Employees Under every Employee
#include<bits/stdc++.h>
using namespace std;
void group(char lisa[][2],int x)
{
unordered_map<char,int>store;
for(int i=0;i<x;i++)
{
int a=lisa[i][1];
int b=lisa[i][0];
if(store.find(lisa[i][1])!=store.end())
{
if(store.find(lisa[i][0])!=store.end())
store[a]=store[b]+store[a]+1;
else
store[a]=store[a]+1;
}
else
store[a]=1;
}
for (auto data : store)
{
cout<<"Key = "<<data.first<< ", Value = "<<data.second<<endl;
}
}
int main()
{
char lisa[6][2];
lisa[0][0]='A';
lisa[0][1]='C';
lisa[1][0]='B';
lisa[1][1]='C';
lisa[2][0]='C';
lisa[2][1]='F';
lisa[3][0]='D';
lisa[3][1]='E';
lisa[4][0]='E';
lisa[4][1]='F';
lisa[5][0]='F';
lisa[5][1]='F';
group(lisa,6);
}[[A,C],[B,C],[C,F],[D,E],[E,F],[F,F]]
{{A:0},{B,0},{C,2},{D,0},{E,1},{F,5}}Complexity Analysis
Time Complexity=O(N)
As we run a single loop going through all the elements
Space Complexity=O(N)
As we use a HashMap to store all the key-value pairs
A Small Tweak
Now, we are having not just the employee under employee data but are provided with the importance of each employee as well. We are having the mammoth task of reporting the sum of importance under every manager.
Let us go through the process one by one as we perform BFS to look into eligible data
- Firstly, we are putting elements in a queue.
- We will continue to look into the next possibilities until this queue gets empty
- Secondly, we get the topmost element from the queue
- We get the list of employees undertaken by the employee
- We are putting all these employee codes in our stack
- At the same time, we are adding the importances we have encountered
- Thus, until the queue gets empty we will have all the importances ready
Java Code for Find Number of Employees Under every Employee
class Solution
{
public int getImportance(List<Employee> employees, int id)
{
int sum=0;
Queue<Integer>trav=new LinkedList<>();
trav.add(id);
while(!trav.isEmpty())
{
int cur=trav.remove();
for(int i=0;i<employees.size();i++)
{
if(employees.get(i).id==cur)
{
sum=sum+employees.get(i).importance;
List<Integer>nxt=employees.get(i).subordinates;
for(int j=0;j<nxt.size();j++)
trav.add(nxt.get(j));
break;
}
}
}
return sum;
}
}
C++ Code for Find Number of Employees Under every Employee
class Solution
{
public:
int getImportance(vector<Employee*> employees, int id)
{
int sum=0;
queue<int>trav;
trav.push(id);
while(!trav.empty())
{
int cur=trav.front();
trav.pop();
for(int i=0;i<employees.size();i++)
{
if(employees[i]->id==cur)
{
sum=sum+employees[i]->importance;
vector<int>nxt=employees[i]->subordinates;
for(int j=0;j<nxt.size();j++)
trav.push(nxt[j]);
break;
}
}
}
return sum;
}
};[[1,5,[2,3]],[2,3,[]],[3,3,[]]] 1
11
Complexity Analysis
Time complexity=O(V+E)
Space complexity=O(n)
V=Number of Vertices
E=Number of Edges
- Firstly, We are emptying the queue that runs over V times. In the loop
- We are removing data from the queue=O(1) operation
- Traversing all the neighbor edges to get the clones=O(Adj)
- Adding neighbours=O(1) operation
- Lastly,Summing up the complexity=V*(O(1)+O(Adj)+O(1))
- Which boils down to O(V)+O(V*Adj)
- Making the time complexity=O(V+E)
- The space complexity is O(n) as all we needed was a queue