The problem “Remove Duplicates from Sorted List II” states that you are given a linked list that may or may not have duplicate elements. If the list has duplicate elements then remove all of their instances from the list. After performing the following operations, print the linked list at the end.
Table of Contents
Example
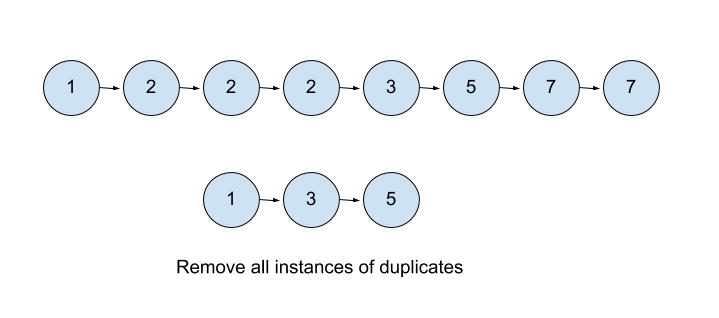
Elements of linked list: 1 2 2 2 3 5 7 7
List after removing all the elements: 1 3 5
Explanation
The number 2 has 3 instances in the list. Thus we removed all of its instances. The same happened with number 7. So after removing all instances of 2 and 7. We are left with only 3 elements which are 1 3 5.
Approach
The problem “Remove Duplicates from Sorted List II”, as stated already asks us to remove all the numbers which have duplicates present in the list. There was a problem once discussed. But there is a slight difference in the current problem. The earlier problem asked us to delete only the duplicates. That is we deleted the duplicates but a single copy of the element whose duplicates were present was not removed. Here we have to delete each and every copy and the original element as well which had its duplicates in the list.
So, now we are familiar with the problem. We can think of ways to tackle the problem. We already know that the list is sorted. So we can use this fact. If the list is sorted, we are sure that if there exists any duplicate. They always occur in a group. So, we just need to check adjacent elements for duplicates. If we come across such a pair. First, we traverse the list until we find a non-duplicate element or the list ends. At that point, we point the previous node to this new non-duplicate element. Then again start searching for duplicate elements from this non-duplicate element.
By the term “non-duplicate”, we do not mean that the current element does not have any duplicates in the list. It just means that the current node is not equal to this element. Consider, we have 1, 2, 2, 2, 3, 3 in the list. We point the 1 to 3. However, 3 will also be removed. But at some point in time, when we were checking for adjacent elements and came across the first 2 2 pairs. We say that 3 is a non-duplicate because it is not 2.
So, to summarise this. We simply traverse the list. And keep on checking if the next element is the same as that of the current element. If that happens then keep on removing elements until you find a non-duplicate element.
Code
C++ code to Remove Duplicates from Sorted List II
#include <bits/stdc++.h>
using namespace std;
struct ListNode{
int data;
ListNode *next;
};
ListNode* create(int data){
ListNode* tmp = new ListNode();
tmp->data = data;
tmp->next = NULL;
return tmp;
}
ListNode* deleteDuplicates(ListNode* head) {
if(head==NULL || head->next==NULL)
return head;
ListNode* prev = create(-1);
ListNode* dummy = prev;
ListNode* cur = head;
prev->next = cur;
while(cur && cur->next) {
if(cur->data == cur->next->data) {
while(cur->next && cur->data==cur->next->data) {
ListNode* tmp = cur;
cur = cur->next;
free(tmp);
}
prev->next = cur->next;
free(cur);
cur = prev->next;
} else {
prev = cur;
cur = cur->next;
}
}
return dummy->next;
}
void printLinkedList(ListNode *headA){
while(headA != NULL){
cout<<headA->data<<" ";
headA = headA->next;
}
}
int main(){
ListNode *headA = create(1);
headA->next = create(2);
headA->next->next = create(2);
headA->next->next->next = create(2);
headA->next->next->next->next = create(3);
headA->next->next->next->next->next = create(5);
headA->next->next->next->next->next->next = create(7);
headA->next->next->next->next->next->next->next = create(7);
headA = deleteDuplicates(headA);
printLinkedList(headA);
}1 3 5
Java code to Remove Duplicates from Sorted List II
import java.util.*;
class ListNode{
int data;
ListNode next;
}
class Main{
static ListNode create(int data){
ListNode tmp = new ListNode();
tmp.data = data;
tmp.next = null;
return tmp;
}
static ListNode deleteDuplicates(ListNode head) {
if(head==null || head.next==null)
return head;
ListNode prev = create(-1);
ListNode dummy = prev;
ListNode cur = head;
prev.next = cur;
while(cur != null && cur.next != null) {
if(cur.data == cur.next.data) {
while(cur.next != null && cur.data==cur.next.data) {
ListNode tmp = cur;
cur = cur.next;
}
prev.next = cur.next;
cur = prev.next;
} else {
prev = cur;
cur = cur.next;
}
}
return dummy.next;
}
static void printLinkedList(ListNode headA){
while(headA != null){
System.out.print(headA.data+" ");
headA = headA.next;
}
}
public static void main(String[] args){
ListNode headA = create(1);
headA.next = create(2);
headA.next.next = create(2);
headA.next.next.next = create(2);
headA.next.next.next.next = create(3);
headA.next.next.next.next.next = create(5);
headA.next.next.next.next.next.next = create(7);
headA.next.next.next.next.next.next.next = create(7);
headA = deleteDuplicates(headA);
printLinkedList(headA);
}
}1 3 5
Complexity Analysis
Time Complexity
O(N), because we are traversing over the elements exactly one. Thus the time complexity is linear.
Space Complexity
O(1), because we have used constant elements. Thus the space complexity is constant.