Decision Tree is a decision support tool that helps us for finding the best result. It’s used to classify and predict some tasks in an efficient way. Decision_Tree is a type of flowchart which we can represent in the tree data structure. In decision tree nodes are denoting tests on some attributes. Edges of the decision_trees represent the result or outcome of the attribute.
Note: In decision tree leaf nodes representing a particular type of class label.
Table of Contents
Example of Decision Tree
Let see one simple example of a decision_tree. In this example, we are talking about the loan company. A loan company makes a decision tree for which category how much percentage of users take a loan. See the below diagram of the decision tree for the loan company.
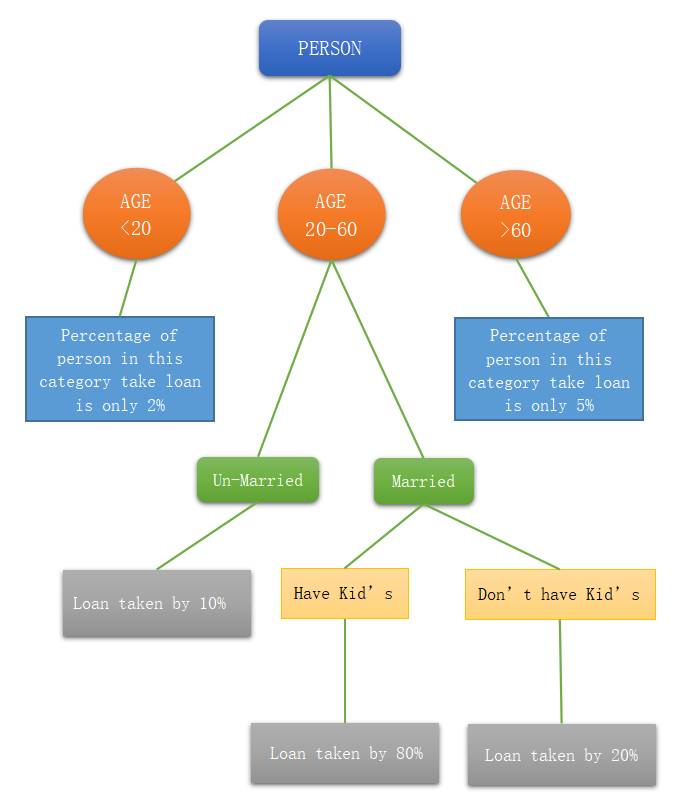
So, the loan company gives much preference to the category of a married person who has kids. This is the best example of how marketing is done by any loan company.
Terms used in Decision Tree
Root Tree
It represents the whole data set which we divide into subcategory on different-different bases. Here whole data set represent the universal set of the sample or the whole population.
Leaf Node
It represents the class label and not further divided into subsets. If we want the result of any decision then we go to the leaf node for that decision and get the result.
Decision Node
When we able to divide the node into sub-nodes then we say the parent node is our decision node. Root and intermediate nodes are our decision nodes.
Parent/Child Node
Those nodes which we can divide into sub-nodes or child nodes is called the parent of their sub-nodes. Sub nodes of decision nodes are our child nodes.
Splitting
It’s a process in which we divide the decision nodes into some sub-set nodes. We divide our decision nodes on the base of attributes given to us.
Pruning
When we remove or delete the child node of a parent node then this process is called pruning. In other words we say that pruning is the opposite of splitting.
Sub-tree
Part of the decision tree is called the sub-tree. Part means either we take the left sub-tree from any node or take the right sub-tree from any node.
Working Process
It’s a type of supervised learning algorithm in which we have already a dataset of target variables. In the real world, we use a decision tree where the concept of classification comes. It works for the set of contiguous input variables. In this, we divide set into subsets on the basis of different attributes. We do splitting and pruning as per the desired result which we want.
Algorithm Used
Step:1 Choose the best attribute using Attribute Selection Measures(ASM) to divide the records into sub-records.
Step:2 Make that current node to a decision node and split the dataset into smaller subsets.
Step:3 Build Decision tree until by repeating this process recursively for each child until one of the below condition will match:
a) Reached to the leaf node or current tuples belong to the same attribute value.
b) There are no more remaining attributes.
c) There are no more instances.Types of Decision Tree
- Continuous Decision Tree: In this type of tree contain contiguous target variables. We use these variables for splitting and pruning.
- Categorical Decision Tree: In this type of tree contain categorical target variables. We use these variables for splitting and pruning.
Advantages
- Easy to handle and understandable by those people who are not familiar with the technical field.
- It’s very useful in data exploration because we can find the variable which is effective for us.
- Decision Tree required less effort from the user side to create the data for the given problem.
- In the decision tree, the data type is not a constraint.
- In decision tree less amount of data cleaning required.
Disadvantages
- May suffer from over-fitting.
- Classifier by rectangular partitioning.
- Hard to handle non-numeric data.
- Can’t create it for the large set.
- If there are many class label then Calculation becomes much complex.