What is Recursion?
Recursion is simply defined as a function calling itself. It uses its previously solved sub-problems to compute a bigger problem.
It is one of the most important and tricky concepts in programming but we can understand it easily if we try to relate recursion with some real examples:
Table of Contents
Example
Think of a situation when you put a mirror in front of a mirror?

This happens because a mirror is reflecting a mirror, which is reflecting a mirror,…and so on.
This is exactly what recursion does.
Now let’s try to visualize how recursion works:
If we define a function to draw a triangle on its every edge. Can you imagine the resultant figure?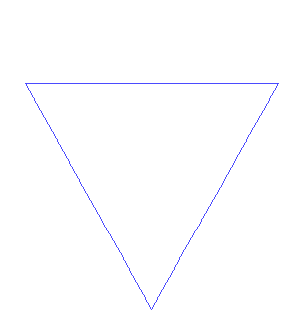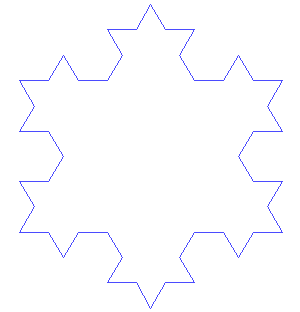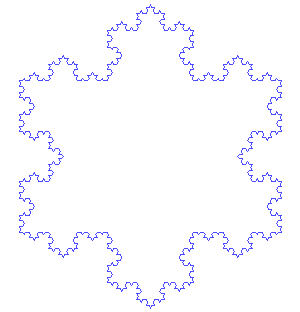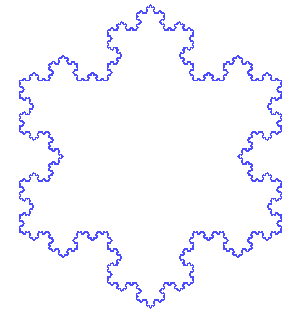
In both the above examples we saw the never-ending sub-problems (the mirrors will keep reflecting one another and there appears to be an infinite number of mirrors and in the second example, the figure will keep growing infinitely).
By this, we understand the need of having an end condition for every recursive function which will avoid this infinite structure. This condition is known as Base Case.
Steps to forming recursion
- Base Case
- Recursive call for the smaller problem
- Computation of bigger problem using solved sub-problems
Let’s try to understand it with an example:
Ques: Calculate the sum of n consecutive natural number starting with 1.
int sum(int n){
// Base Case
if(n==1){
return n;
}
else{
int smallerSum=sum(n-1); //recursive call for smaller problem
return n+smallerSum; // solve bigger problem using solved smaller sub-problems
}
}Recursion and Stack
When a function is called, it occupies memory in the stack to store details about the execution of the function. And when the function ends, the memory occupied by it is also released. Now in recursion, as we know a function is called in itself. Hence at every function call, a block of memory is created in the stack to hold the information of the currently executing function. When the function ends, it returns to it’s calling statement written in the outer function i.e., an outer function is resumed from where it stopped. Let’s see the memory structure in the above example for n=3:

Keeping the association of recursion and stack in mind, we can easily understand that in absence of Base Case, our program will suffer with Stack overflow and time limit exceeded.
Difference Between Direct and Indirect Recursion
Direct Recursion
- When the same function calls itself then it is known as Direct Recursion.
- In Direct Recursion, both calling and called function is the same.
- There will be a one-step recursive call.
The code structure of Direct Recursive function:
return_type func_name(arguments)
{
// some code...
func_name(parameters);
// some code...
}Indirect Recursion
- When a function calls another function which is also calling its parent function directly or indirectly then it is known as Indirect Recursion.
- In Indirect Recursion, calling and called functions are different.
- There will be a multi-step recursive call.
The code structure of the Indirect Recursive function:
return_type func_name1(arguments)
{
// some code...
func_name2(parameters);
// some code...
}
return_type func_name2(arguments)
{
// some code...
func_name1(parameters);
// some code...
}Types of Recursion
- Tailed Recursion
- When the last executed statement of a function is the recursive call.
- It is possible to keep only the last recursive call on the stack.
- Example:
int sum(int n,int &ans){
if(n==0){
return ans;
}
else{
ans=ans+n;
return sum(n-1,ans); // last statement to be executed is recursive call
}
}- Non-tailed Recursion
- When there are statements left in the function to execute after recursive call statement.
- Recursive call will remain in the stack until the end of its evaluation.
- Example:
int sum(int n){
if(n==1){
return n;
}
else{
int smallerSum=sum(n-1); //recursive call for smaller problem
return n+smallerSum; //statements to be executed after recursive call
}
}
When to use recursion over iteration
Both approaches have their own pros and cons, hence it becomes necessary to understand which one should be used to solve a particular problem.
Recursive is a more intuitive approach for solving problems of Divide and conquer like merge sort as we can keep breaking the problem into its sub-problems recursively which is sometimes difficult to do using an iterative approach, for example, Tree traversal(Inorder, Preorder, Postorder). But it is also true that the iterative approach is faster than recursion as there is no overhead of multiple function calls.
Note:To solve a problem we can use iteration or recursion or even both.
Recursion can be replaced by iteration with an explicit call stack, while iteration can be replaced with tail_recursion. We as a programmer should create a balance between easy and clean writing of code with memory and time optimization.
Let’s try to solve another question:
Calculate factorial of n.
C++ implementation
#include <iostream>
using namespace std;
int fact(int n){
// Base Case
if (n <= 1)
return 1;
else
return n*fact(n-1);
}
int main(){
int n=5;
cout<<fact(n);
return 0;
}
Output: 15
Java implementation
class Main{
static int fact(int n){
if (n<=1)
return 1;
else
return(n * fact(n-1));
}
public static void main(String args[]){
int n=5;
System.out.println(fact(n));
}
}
Output: 15
Thanks for reading!!
Stay tuned and check out the other blogs too. Comment down for any corrections/suggestions.